fpdf2, the library I mentioned in my previous post, cannot parse existing PDF files.
However, other Python libraries can be combined with fpdf2
in order to add new content to existing PDF files.
[EDIT 2024/12/17] : those examples are now included in the official fpdf2 documentation:
Demo
In order to demonstrate this using an actual example,
I first generated a PDF of some code snippet using the src2pdf bash function described in an old article on syntax coloring:
add_on_page.pdf (PDF 1 page 30 Ko)
And then I added the following official Python logo to it:
![]()
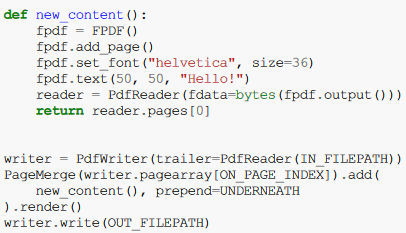
There is the new_content function I used:
def new_content():
fpdf = FPDF()
fpdf.add_page()
fpdf.image("python-logo.png", x=0, y=120)
reader = PdfReader(fdata=bytes(fpdf.output()))
return reader.pages[0]
And there is the result: add_on_page_with_python_logo.pdf (41 Ko).
")













