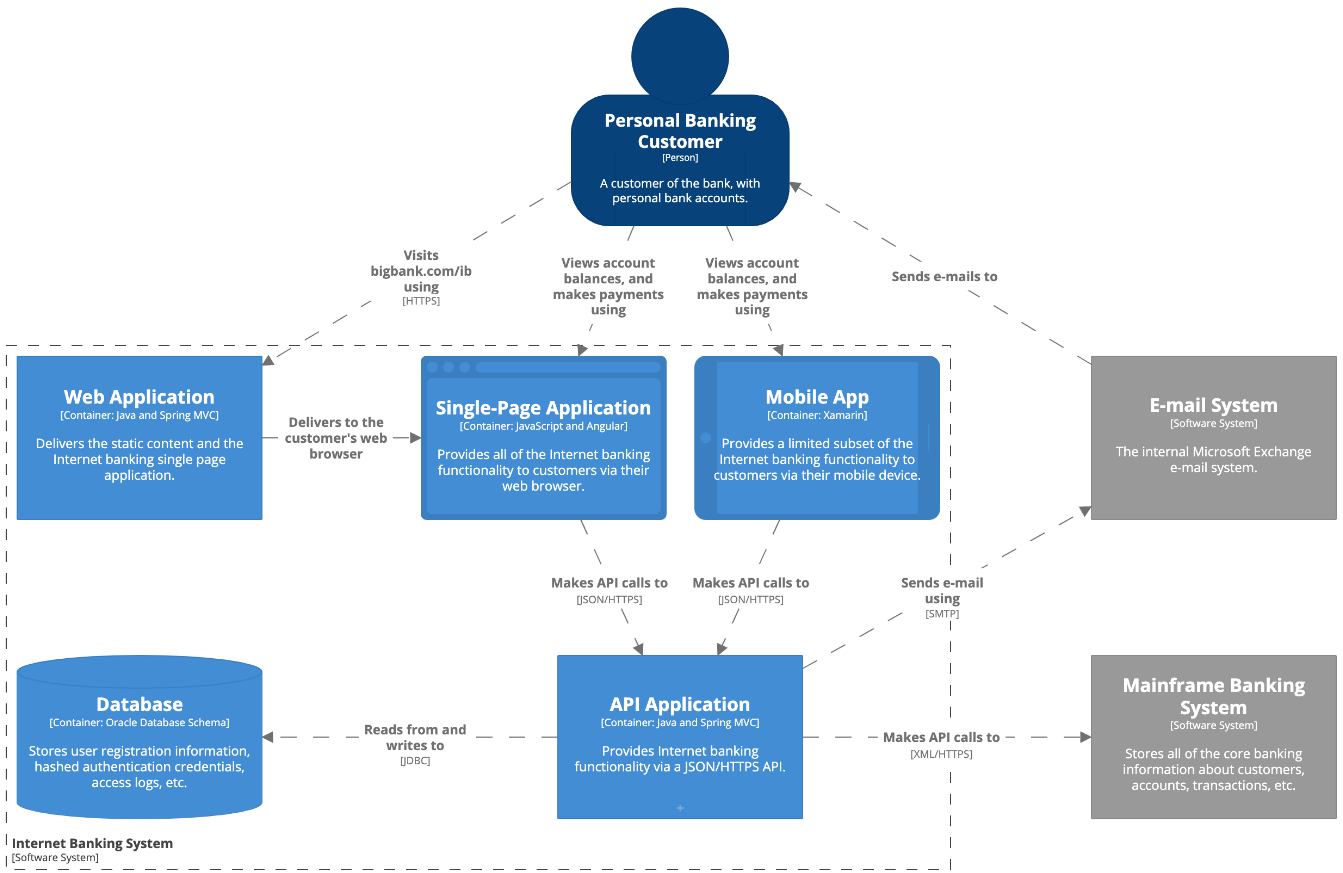
J’ai découvert il y a quelques temps le C4 model. C’est une méthodologie permettant de modéliser et documenter l’architecture logicielle d’un système logiciel. Cela m’a tout de suite intrigué et pourra intéresser ceux qui connaissent un peu l’état de l’art sur ce sujet.
I have this piece of advise in my software engineer notes since 2015.
Just thought it would be nice to re-post / share it again.
Transmodel is the basis for defining exchange standards that enable the sharing and provision of accurate and interoperable public transport information across organisation- and system-boundaries.
How inappropriate data access patterns massively slow down programs and how the same problems arise with RESTful APIs.
Retrieving whole rows is hugely wasteful when only part of the row is required to resolve a user request. The issue becomes pronounced when: retrieving sub-parts of the data (projection), consulting multiple tables (joins) or digesting the dataset (aggregation).
RESTful API design consequently suffers the same problems as Active Record ORMs. [...] The largest class of API clients is separated from the server by high latency network links: mobile phones. [...] This means that accessing multiple API endpoints to resolve a single user request can take seconds - an appreciable annoyance to any user.
From ORMs: demand first class queries and transactions. Avoid Active Record style access patterns whether in ORMs or elsewhere.
Un résumé de Domain Driven Design d’Eric Evans
par Abel Avram & Floyd Marinescu
(click on the title to access full article on medium.com)
tl;dr limitations & pitfalls:
- Eventual Consistency : that queue between the write and read model can fill up
- Whole system fallacy : CQRS is not an architectural pattern and should not be applied to a whole system
- Task based UIs : they focus their design on the user intent.[...] your events will be based on a SomethingCreated or SomethingUpdated which has no business value at all. If the events are being designing like this then it is clear you’re not using DDD at all and you’re better of without event sourcing
- Event schema : managing these changes is one of the most complex and error prone drawbacks associated with event sourcing. A strategy should be prepared upfront and considered on the system design.
- Event granularity : have your commands and events reflecting the intent of the user staying true to DDD [...] it’s very easy to choose the wrong design.
- Operation flexibility : to undo an action means sending the command with the opposite action. It is harder to affect multiple entities and requires a knowledge of the system, not like SQL that everyone knows
Based on Clean Architecture, by Robert Martin,
with code examples and detailed explanations.
"Devs should be able to run entire env locally. Anything else is just a sign of bad tooling"
"pre-production testing is a best effort verification of a small subset of the guarantees of a system and often can prove to be grossly insufficient for long running systems with protean traffic patterns"
"The writing and running of tests is not a goal in and of itself — EVER. We do it to get some benefit for our team, or the business"
"there are coverage based fuzzers like afl as well as tools like the address sanitizer, thread sanitizer, memory sanitizer, undefined behavior sanitizer and the leak sanitizer to name a few."
"This was but one example of a system that didn’t stand much to benefit from integration testing and where monitoring has worked much better."
vendor-neutral open source library for metric collection and tracing. OpenCensus is built to add minimal overhead and be deployed fleet wide, especially for microservice-based architectures.
OpenCensus currently supports Prometheus, SignalFX, Stackdriver, Zipkin, Datadog, and Azure App Insights.
A single set of libraries for many languages, including Java, C++, Go, .Net, Python, PHP, Node.js, Erlang, and Ruby.
designed for microservices, cloud native and container-based (Docker, K8s, Mesos) architectures. Underlying technology is a distributed tracing system.
- Provide high performance Java agent, no need to CHANGE any application source code.
Only increase extra 10% cpu cost in 5000+ tps application, even when collect all traces. - Manual instrumentation
- As an OpenTracing supported tracer
- Use @Trace annotation for any methods you want to trace.
- Integrate traceId into logs for log4j, log4j2 and logback.
"nowadays I think the trend is so anti-framework, and so pro-modularization, tiny libraries that all do their own thing. We’ve all become effectively framework maintainers. Not to say everyone’s inventing their own, but we’re like curators now of like this manifest of here’s my thirty dependencies, and no one else in the world will have all thirty dependencies at exactly the same versions that you do. Which means that now the onus is on you to make sure that they all work together correctly"
"It’s like I don’t get any distinct joy out of this anymore, I’m mostly just doing work for people for free, and they don’t really appreciate it because they’re used to it now.
So do I continue out some sort of misplace sense of duty, or do I just quit and leave people in a lurch. I think that’s how a lot of open source projects slowly atrophy and die."
"Right, so if I’m a maintainer I acknowledge that now, after writing this talk and thinking about this a lot is like, okay so this project is a hundred stars, like I really shouldn’t be the only owner on this repo or this NPM library, or this ruby gem. Lets pull in a couple other owners because other people are joining and like oh this project is a thousand stars, like lets look at a code of conduct, a governance model, you know some kinda mission statement for what this project’s about, the core tenants."
"That’s what I see on really successful open source teams. Is giving people a reason to fill those roles that isn’t just about money"
"3) Service virtualisation:
- Mountebank
- Wiremock (I used this one: very simple & efficient)
- Stubby4j
- VCR / Betamax
- Hoverfly"
"This might seem strange, because most of the articles on microservices are extolling their countless virtues like decoupling tech systems, better horizontal scalability, removing dependencies between development teams, and so on."
...
"Usually, in growth-stage startups, the main motivation for moving to microservices is that hope that doing so will remove dependencies between development teams and/or improve the ability of the system to handle larger traffic loads (i.e., scalability)."
...
"As is often the case for tech people who have limited experience, they reach for a technical solution to a people problem, and decide they need microservices in order to reduce dependencies or coupling between dev teams."
This article describes the increasingly popular Microservice architecture pattern, used to architect large, complex and long-lived applications as a set of cohesive services that evolve over time.
What are the practical concerns associated with running microservice systems? And what you need to know to embrace the power of smaller services without making things too hard? At last GeeCon 2014 in Krakow, Sam Newman tried to answer those questions by giving 14 tips about how microservices can interface, how the can be monitored, deployed, and made safer.